Rows: 13,932
Columns: 17
$ LATITUDE <dbl> 25.89103, 25.89132, 25.89133, 25.89176, 25.89182, 25…
$ LONGITUDE <dbl> -80.16056, -80.15397, -80.15374, -80.15266, -80.1546…
$ PARCELNO <dbl> 622280070620, 622280100460, 622280100470, 6222801005…
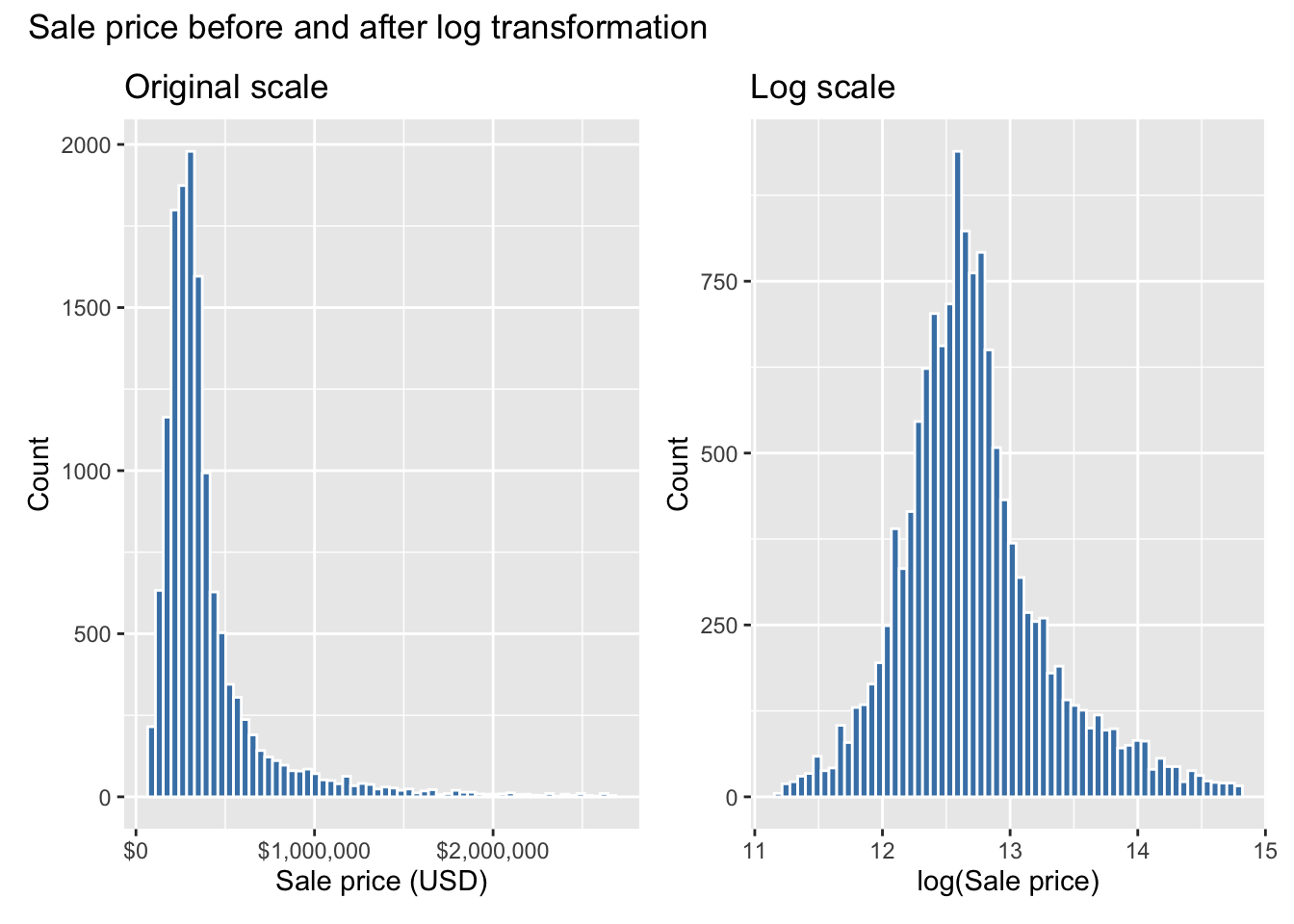
$ SALE_PRC <dbl> 440000, 349000, 800000, 988000, 755000, 630000, 1020…
$ LND_SQFOOT <dbl> 9375, 9375, 9375, 12450, 12800, 9900, 10387, 10272, …
$ TOT_LVG_AREA <dbl> 1753, 1715, 2276, 2058, 1684, 1531, 1753, 1663, 1493…
$ SPEC_FEAT_VAL <dbl> 0, 0, 49206, 10033, 16681, 2978, 23116, 34933, 11668…
$ RAIL_DIST <dbl> 2815.9, 4359.1, 4412.9, 4585.0, 4063.4, 2391.4, 3277…
$ OCEAN_DIST <dbl> 12811.4, 10648.4, 10574.1, 10156.5, 10836.8, 13017.0…
$ WATER_DIST <dbl> 347.6, 337.8, 297.1, 0.0, 326.6, 188.9, 0.0, 10.5, 5…
$ CNTR_DIST <dbl> 42815.3, 43504.9, 43530.4, 43797.5, 43599.7, 43135.1…
$ SUBCNTR_DI <dbl> 37742.2, 37340.5, 37328.7, 37423.2, 37550.8, 38176.2…
$ HWY_DIST <dbl> 15954.9, 18125.0, 18200.5, 18514.4, 17903.4, 15687.2…
$ age <dbl> 67, 63, 61, 63, 42, 41, 63, 21, 56, 63, 64, 51, 56, …
$ avno60plus <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ month_sold <dbl> 8, 9, 2, 9, 7, 2, 2, 9, 3, 11, 2, 11, 7, 7, 9, 11, 6…
$ structure_quality <dbl> 4, 4, 4, 4, 4, 4, 5, 4, 4, 5, 4, 2, 2, 2, 5, 2, 2, 4…